Assignment:
Assignment One requires you to develop a multiple regression model. The
assignment is described on a separate page.
Note:
Regression is a powerful, complex tool with MANY variations and requirements.
Please refer to the class readings for a comprehensive discussion. These
notes are merely to supplement the required readings.
What is regression? Depending on your goal and priorities and
perspective, it is:
- a powerful statistical method to test the strength and significance of
relationships between variables
- the search for (usually linear) patterns in the mess of scatterplots
- a technique to develop an explanatory model (what explains the variation
in the dependent variable Y?)
- a technique to develop a predictive model (given specific values for the
independent variables, what is our best estimate of Y?)
- a way to isolate the influence and significance of one variable (x) on
another (y) by controlling for all the other independent variables (e.g.,
to isolate the role of race or gender on income levels controlling for education,
years of experience, etc.)
- the hardest, most complex technique learned in a first-semester statistics
course
- the hunt for a high R-square (though this is NOT necessarily a legitimate
goal for regression)
- based on the assumption that there is some common, underlying relationship
between the variables that can be isolated and measured by controlling for
all the other variables.
Resources to download
--------------
The main goals of learning for this section on regression:
1. how to use regression to address research questions
2. how to use regression equations for predictions
3. using multiple regression to see the unique influence of individual variables
4. knowing when a relationship is significant.
5. understanding the role of linearity, multicollinearity, residuals, outliers.
6. know when regression results might be misleading
Key Terms include:
dependent variable (explained)
independent variable (explanatory variable)
degrees of freedom
linear and nonlinear |
error
residuals
sum of squares
OLS - Ordinary Least Squares |
multicollinearity
dummy variable (a categorical variable coded as 0 or 1 so that it can act
as an independent variable) |
Readings
Lewis-Beck, Michael S. 1980. Applied Regression: An Introduction. Newbury
Park, CA: Sage.
The Role of b, Beta, t, R-square and F:
|
each individual independent variable |
the model as a whole |
| strength of the relationship |
b (partial regression coefficient);
or for better comparison between variables, use: Beta
weights (standardized b) |
R
2
(for models with many variables, also look at the adjusted
R2) |
| statistical significance |
t score |
F score |
These are therefore desirable features of a regression model
|
each individual independent variable |
the model as a whole |
| strength of the relationship |
large Beta weights (their
absolute values) (though if the t, R2 and F are all "ok" then don't
worry directly about the value of b and Beta.) |
a high R2 (closer
to 1 than 0) that is, most of the variation in Y explained. |
| statistical significance |
a high and thus significant t score (generally,
|t| > 2. (remember: ALL variables in a model need to be stat.
significant) |
a high and thus significant F (see
the F table, but generally above about 4 to be sign. at .05 level) |
In addition, error terms have a constant variance, no or only a few
outliers, error terms normally distributed, little multicollinearity (independent
variables that are highly correlated), etc.
Overview of regression statistics and their use:
| statistic |
formula |
Questions we ask |
| b |
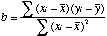 |
As x increases by one unit, how much does Y increase?
(use to construct the regression equation). known as the regression
coefficient, or in multiple regression as the "partial regression coefficient" |
| Beta weights |
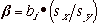 |
standardized regression coefficient. As x increases
by one standard deviation, how much does Y increase (in standard deviations)?
Useful to compare the relative explanatory power of different independent
variables (especially when ind. variables have different measurement scales).
Beta weights can be interpreted like partial r (correlation coefficients). |
| a |
a = y - bx |
What is the y-intercept? (That is, when x = 0, what
is y?). Sometimes this value has real meaning, sometimes not.
Generally, when the y-intercept falls within the range of data values, it
will be more meaningful than when it falls outside the range of data values. |
| t |
t = b / std. error |
What is the statistical significance of the relationship
between this independent variable and the dependent variable (controlling
for the other variables in the model)? (SPSS calculates the probability
of this t score being due to just random chance, labeled "Sig" for "Significance",
where the number represents the chances out of 1 that the measured difference
might be just due to random chance.) Generally we consider variables
with Sig values < .05 to be statistically significant. |
| R2 |
 |
What percent of the total variation in the dependent variable
is explained by the independent variables in the model? R-square =
explained (or regression) sum of squares / total sum of squares.
or R-square = RSS / TSS = 1 - (SSE / TSS) |
| F |
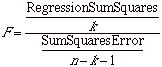
or
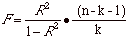
|
What is the statistical significance of the
model as a whole? (SPSS calculates a significance level for this,
similar to that for the t scores.) |
|
|
|
| k |
. |
the number of independent variables |
| n |
. |
the number of cases |
| degrees of freedom |
for regression (explained): k
for residual (unexplained): n - k -1
total: n - 1 |
Not itself interpreted, but used to calculate the other statistics;
defined (Blalock, 205): "equal to the number of quantities that are unknown
minus the number of independent equations linking these unknowns."
that extra one degree lost is due to the dependent variable |
|
|
|
Some terms
F-Score
The F-score from the ANOVA table (Analysis of Variance) allows one to determine
the probability of getting these regression results if there was no difference
in the population as a whole. What is a significant F-score? It depends on the
degrees of freedom (both the number of independent variables, k, and the total
number of cases, n, or more precisely, n- k-1). See an F-table (in the back
of stat books). For example, with 4 independent variables and 30 cases, F is
significant at the p=.05 level when F>2.76. With 4 variables and 125 cases,
the threshold is F>2.45. (You will generally find that your regression models
will always have stat. significant F-scores; it is harder to develop a powerful,
meaningful model where all of the variables have stat. significant t-scores.)
Beta weights
Beta weights are adjusted partial slopes, or standardized B's. [see Lewis-Beck,
p. 64] To calculate, multiply the b by the standard deviation of the dependent
variable (x), and divide by the standard deviation of the independent variable
(y). Beta weights are useful for comparing the relative importance of each independent
variable. Compare the absolute values of the beta weights.
(For example: if your model has two independent variables -- the first with
a Beta weight of -0.566 and the second with a Beta weight of 0.231 -- the first
variable is a more powerful explanatory variable in the model.)
What is an "Adjusted" R-Square?
The Adjusted R-Square takes into account not only how much of the variation
is explained, but also the impact of the degrees of freedom. It "adjusts" for
the number of variables use. That is, look at the adjusted R- Square
to see how adding another variable to the model both increases the explained
variance but also lowers the degrees of freedom.
Adjusted R2 = 1- (1 - R2 )((n - 1)/(n - k - 1)). As the number of variables
in the model increases, the gap between the R-square and the adjusted R-square
will increase. This serves as a disincentive to simply throwing
in a huge number of variables into the model to increase the R-square.
Ordinary Least Squares (OLS)
In regression the goal is to find the best fitting equation that links the independent
variables with the dependent variable. This is one that minimizes the
error of prediction. How is this error minimized? A simple approach
is to simply minimize the sum of squares (i.e., "least squares") of
the vertical distances between the estimate line (estimate) and the actual value
of y. (This is SSE - the sum of the square of errors). There are
numerous other methods (and advantages of each), such as weighted least squares
(WLS), 2-Stage Least Squares (2SLS), etc.
Thus: OLS is a method that estimates an equation for the regression line by
minimizing the sum of the square of differences between the actual value of
each case and its predicted value:

Why might an R-Square be less than 1.00?
- underdetermined model (need more variables)
- nonlinear relationships
- measurement error
- sampling error
- not fully predictable/explainable even with all data available; there is
a certain amount of unexplainable chaos/static/randomness in the universe
(which may be reassuring)
- the unit of analysis is too aggregated (e.g., you are predicting mean housing
values for a city -- you might get better results with predicting individual
housing prices, or neighborhood housing prices).
Is an R-Square < 1.00 Good or bad?
This is both a statistical and a philosophical question;
It is quite rare, especially in the social sciences, to get an R-square that
is really high (e.g., 98%).
The goal is NOT to get the highest R-square per se. Instead, the
goal is to develop a model that is both statistically and theoretically
sound, creating the best fit with existing data.
Do you want just the best fit, or a model that theoretically/conceptually makes
sense?
Yes, you might get a good fit with nonsensical explanatory variables.
But, this opens you to spurious/intervening relationships. THEREFORE: hard to
use model for explanation.
What is needed to run a regression
- at least two variables (both interval)
- enough cases to be statistically significant
- some basic computations; can do by hand, with a calculator, with Excel
by calculations, or EXCEL regression function; of a dedicated stat program,
such as SPSS, SAS, Systat, etc.
- an understanding of the requirements of regression so that you don't violate
some basic statistical rules.
From Bivariate to Multiple regression: what changes?
- potentially more explanatory power with more variables.
- the ability to control for other variables: and one sees the interaction
of the various explanatory variables. partial correlations and multicollinearity.
- harder to visualize drawing a line through three+ n-dimensional space.
- the R is no longer simply the square of the correlation statistic r.
Regression Assumptions include:
- linear relationship
- error terms have a constant variance
- no or only a few outliers (always nice to be able to explain why)
- error terms normally distributed
- error terms independent
- little multicollinearity (independent variables that are highly correlated)
see Blalock, 485. PROBLEMS: more ambiguity in causal interpretations; partial
correlations and slope estimates become more sensitive to sampling (deviations
from a representative sample) and measurement (problems with our measures)
errors.
- SO: if one has lots of multicollinearity, then one needs BOTH large samples
and accurate measurement.
- we will see examples of this in the fertility example: e.g., variables
that are all affected by the level of development (literacy, wealth, life
expectancy), and culture.
Residual Plots and Regression Assumptions
Recall that there are three basic assumptions about the random deviations (errors),
: the random deviations are independent, normally distributed, and have a constant
variance. In simple linear regression, we also assume that Y and X are linearly
related. We shall consider the use of residual plots for examining the following
types of departures from the assumed model.
1. The regression function is not linear.
2. The error terms do not have a constant variance.
3. The model fits all but one or a few outlying observations.
4. The error terms are not normally distributed.
5. The error terms are not independent.
>>> see Lewis-Beck (Applied Regression),
page 26, for a good discussion of these assumptions <<<
The common graphical tools for assumption checking includes:
1. Residual Plot- scatter plot the residuals against X or the fitted
value.
2. Absolute Residual Plot- scatter plot the absolute values of the residuals
against X or the fitted value.
3. Normal Probability Plot of the Residuals.
4. Time Series Plot of the Residuals - scatter plot the residuals against
time or index.
5. The time series plot of the residuals are strongly recommended whenever
data are obtained in a time sequence. The purpose is to see if there is any
correlation between the error terms over time (the error terms are not independent).
When the error terms are independent, we expect the residuals to fluctuate in
a more or less random pattern around the base line 0.
Further Issues:
1. non-linear transformations
2. dummy variables
3. what to do with ordinal variables
4. WLS - weighted least squares.
5. handling interaction between independent variables, that is, multiplicative
relationships. (not the assumption with OLS that the influences of ind. variables
are additive). e.g., in a JTPA program, to increase ones wage, one may need
BOTH job training and additional attributes): one alone won't do as much. That
is, each alone raises wages by $1000/year, but together the effect is +$7,000.
{this is handling interaction as crossproducts} see Blalock, 492.
Other Techniques
what to do when the dependent variable is not an interval variable? logit, probit,
maximum likelihood, etc. (see statistics books)