UIC
Multimodality Video Indexing and Retrieval Using Directed Information
Abstract:
We propose a novel framework for multimodal video indexing and retrieval using shrinkage optimized directed
information assessment (SODA) as similarity measure. The directed information (DI) is a variant of the classical mutual
information which attempts to capture the direction of information flow that videos naturally possess. It is applied directly
to the empirical probability distributions of both audio-visual features over successive frames. We utilize RASTA-PLP features
for audio feature representation and SIFT features for visual feature representation. We compute the joint probability density
functions of audio and visual features in order to fuse features from different modalities. With SODA, we further estimate the
DI in a manner that is suitable for high dimensional features p and small sample size n (large p small n) between pairs of videoaudio
modalities. We demonstrate the superiority of the SODA approach in video indexing, retrieval and activity recognition
as compared to the state-of-the-art methods such as Hidden Markov Models (HMM), Support Vector Machine (SVM), Cross-
Media Indexing Space (CMIS) and other non-causal divergence measures such as mutual information (MI). We also demonstrate
the success of SODA in audio and video localization and indexing/retrieval of data with missaligned modalities.
Simulation results:
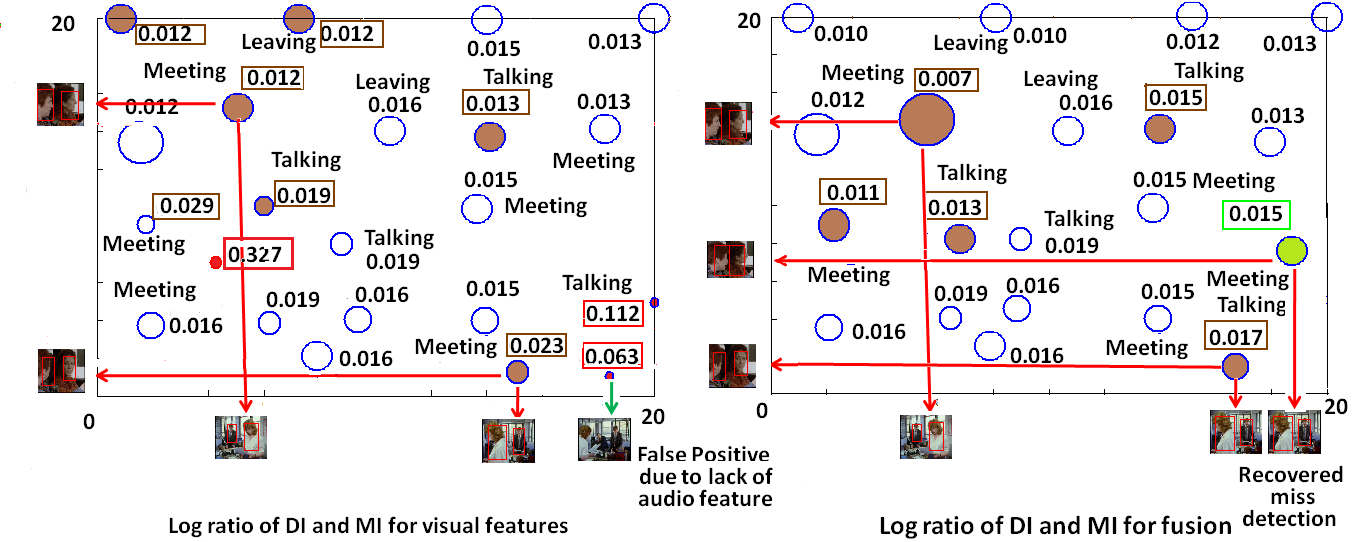
Fig. Bubble graph of log ratio of peak values for local DI with only visual features (left) and with fusion (right) between two videos. Here the axes range represent time shift parameters of
the respective video frames, and the sliding window width is T=5 frames. The size of the bubble is proportional to the log ratio of peak values of DI and MI. Each of the bubbles is annotated by a
particular activity and its p-value. The improvement of p-values with fusion is shown by gray bounding boxes. The removal of false positives is highlighted by red bounding boxes on the left panel.
The improvement of miss detections is highlighted by the green bounding box on the right panel.
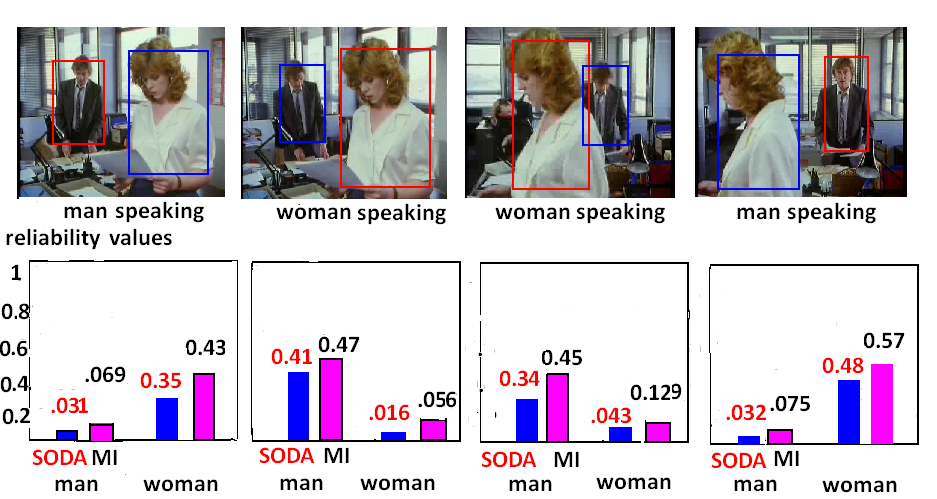
Fig. Top row presents four frames from a video sequence with two speakers in TRECVID dataset. In the first and the fourth frames the man is speaking, while in the second and third frames the woman is speaking. The consistency measure using SODA shown in the bottom row for each frame correctly detects who is speaking and demonstrates the superiority over the MI-based method by Fisher et al, where the vertical axis represents the p-values. The corresponding p-values are annotated at the top of the histograms.
Related publications:
- Xu Chen, Alfred Hero and Silvio Savarese, ''Multimodality video indexing and retrieval using directed information,'' IEEE Transactions on Multimedia (TMM), to appear, 2011.[pdf]
Last updated: May 8, 2011