2.55 Arguments
Category: Philosophy of Mind/Epistemology
Keywords: argument, arguments, premise, thesis, conclusion, defence, conclude, reply, premises, objections, premiss, reject, establish, assumption, objection
Number of Articles: 122
Percentage of Total: 0.4%
Rank: 87th
Weighted Number of Articles: 685
Percentage of Total: 2.1%
Rank: 3rd
Mean Publication Year: 1981.8
Weighted Mean Publication Year: 1981.5
Median Publication Year: 1980
Modal Publication Year: 1971
Topic with Most Overlap: Deduction (0.0345)
Topic this Overlaps Most With: Ontological Argument (0.065)
Topic with Least Overlap: Beauty (0.00044)
Topic this Overlaps Least With: Life and Value (0.00428)
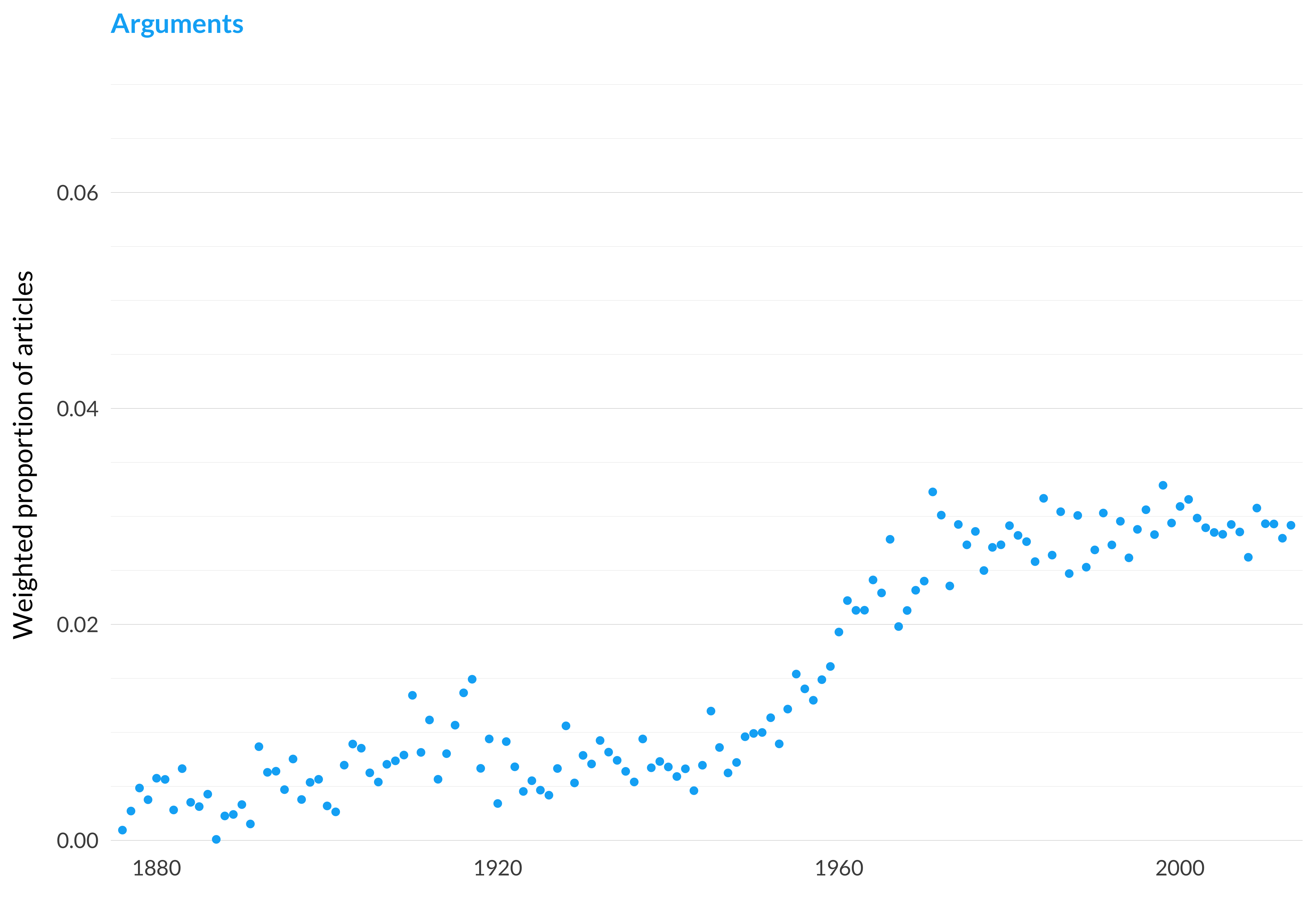
Figure 2.129: Arguments.
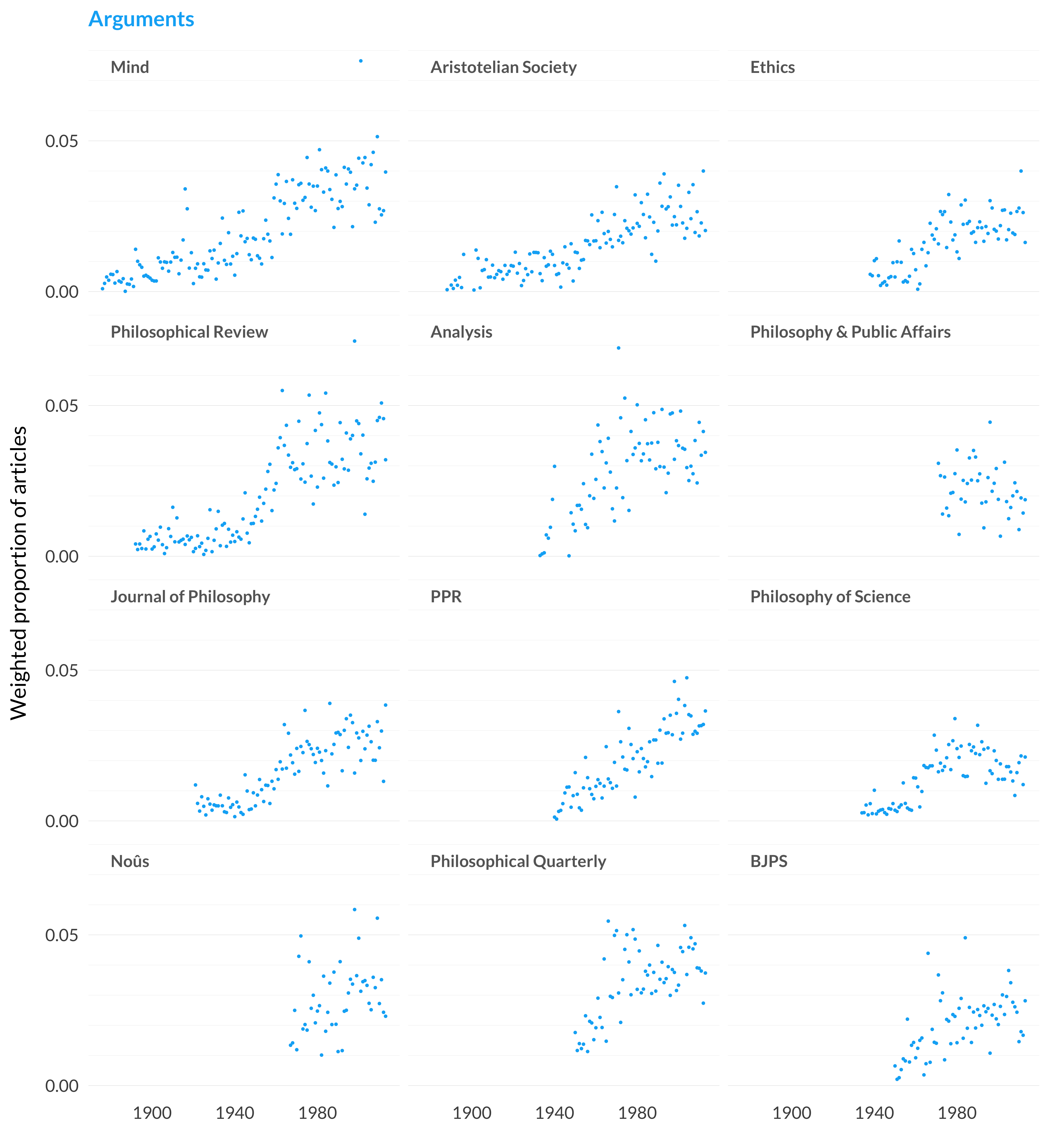
Figure 2.130: Arguments articles in each journal.
Comments
So this is a slightly unfortunate choice that the model made. It notices that there are papers that are about arguments, focusing on things like question begging and circularity. Then it identifies this as a topic, and everywhere someone talks about arguments, it says that maybe that paper should be in this topic. But a lot of philosophy papers talk about arguments! If all papers talked about arguments to the same extent, then the model would zero it all out. But that’s not what happened. It doesn’t even happen to equal amounts over years. This can be seen just by looking at word frequency graphs.
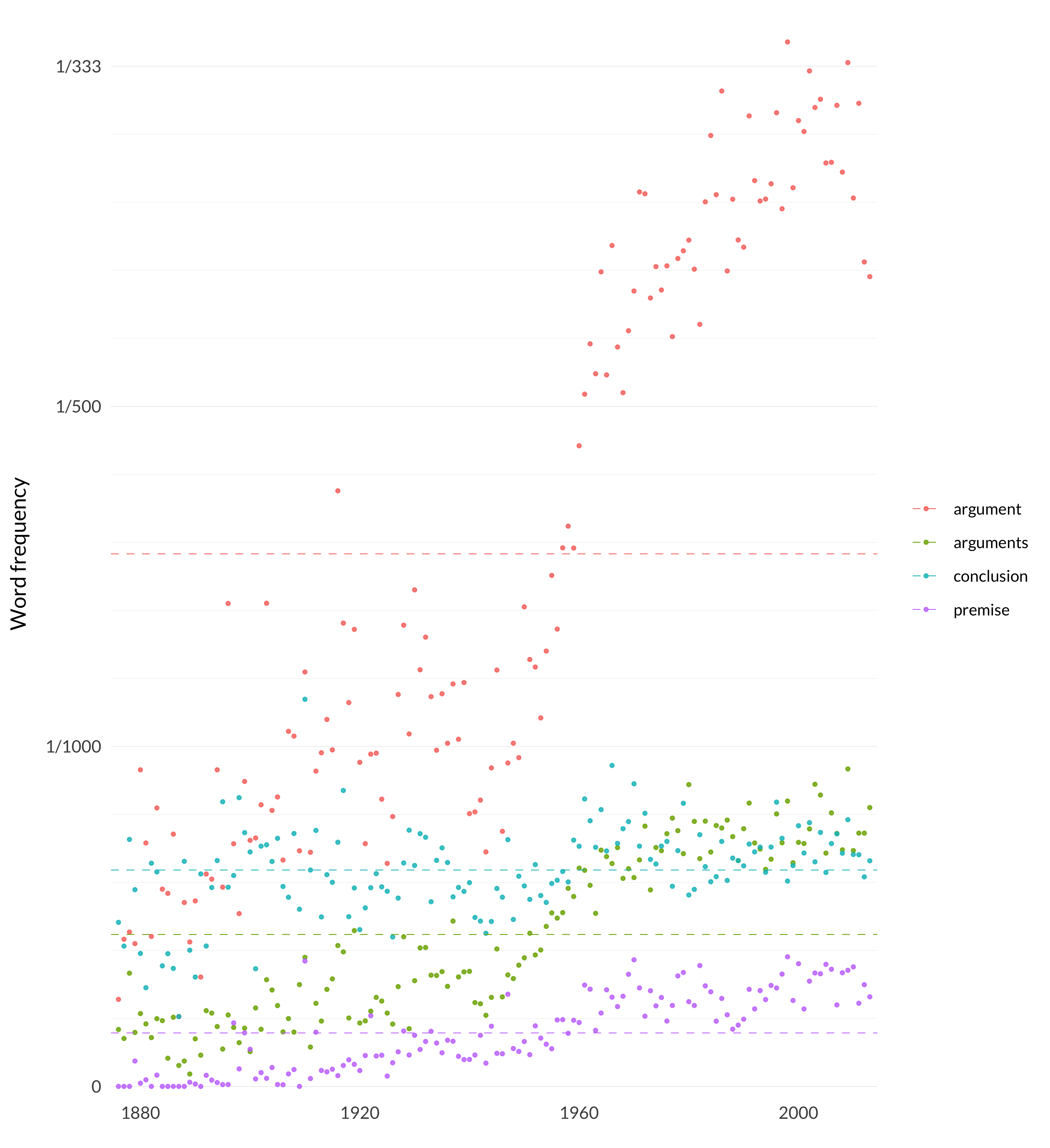
Figure 2.131: Words about arguments.
It’s interesting that premise and conclusion don’t change their frequency over time. But there is a rapid acceleration in how often the word argument is used. And, though I’m not sure the graph makes this clear, arguments also increases too. And note that the word frequency of argument tracks really closely the weighted sum of the topic.
The 122 articles that are primarily in the topic are a somewhat odd group. There are some, as can be seen from the top of the charactistic articles list, that are really about things like circularity. Further down, there are articles that are particularly about arguments for incompatibilism and, especially, arguments for dualism.
This topic has, by a lot, the biggest gap between its raw sum and weighted sum. This is because there are so many articles where the model gives a small, but far from negligible, probability to the article being in the topic. Here’s one way to see that. For each topic, we can ask for how many articles is it the n-th most probable topic. We’ve done that already for n = 1; that’s what the raw count reports. But for this topic the values for n between 2 and 10 are a little eye popping.
| Rank | Number of Articles |
|---|---|
| 1 | 122 |
| 2 | 718 |
| 3 | 1169 |
| 4 | 1344 |
| 5 | 1428 |
| 6 | 1391 |
| 7 | 1379 |
| 8 | 1267 |
| 9 | 1130 |
| 10 | 991 |
For comparison, here’s what that table looks like for causation
| Rank | Number of Articles |
|---|---|
| 1 | 385 |
| 2 | 403 |
| 3 | 377 |
| 4 | 354 |
| 5 | 346 |
| 6 | 353 |
| 7 | 410 |
| 8 | 316 |
| 9 | 376 |
| 10 | 377 |
Here are some of these articles that the model thinks are second most likely to be in arguments. (I’ve restricted this list to articles at least twenty pages long.)
Probably if the model hadn’t landed on this topic, it would have been even clearer that some articles were philosophy of religion articles or ancient philosophy articles.
And this is why this topic is ultimately one I regret having. If I did this whole project over again, I would steer away from models that select topics based on tools, and towards ones that focus more centrally on particular philosophical subject matters.