Ontology-Based Metadata
Click
here to browse the Beethoven knowledge-base.
This page describes the University of Michigan Digital Library (UMDL) Beethoven Project. First, we designed a formal ontology of bibliographic relationships. Then we generated a knowledge-base of metadata from (493) US MARC records on works by or about Beethoven. Our
Java interface lets you browse families of works by navigating relations between works -- a capability not provided by the average library catalog!
Contents:
Bibliographic Relations
Generating the Knowledge-Base
Potential Benefits
People
Publications
Bibliographic relations are relationships between works. They can be quite complex. For example, consider a recording of Beethoven's opera "Fidelio". The recording was performed by an orchestra and singers, based on some arrangement, and might have been remastered at some point. The libretto was originally adapted from a play by J. N. Bouilly, revised several times, and translated from the French. A copy of the score may be available, and perhaps there is also a movie version.
Currently, most catalog information about bibliographic relations is found in notes written in natural language. These notes are certainly valuable for research, but they are difficult to use computationally.
The UMDL Ontology group has developed a formal conceptualization of bibliographic relations. The ontology defines a fairly elaborate structure of precisely defined concepts. For example, instead of talking about a "work", we talk about CONCEPTIONs (associated with the idea), EXPRESSIONs (the work's content), MANIFESTATIONs (the work's publishing format), DIGITIZATIONs (the encoding), and INSTANCEs (the particular copy). A translation and an original work will share the same CONCEPTION. A new edition will share its EXPRESSION with the original, a reprint will share the MANIFESTATION, and so on. Thus works are part of families. Families are structured as trees. Each kind of relationship between works is located at a certain level in the structure (see Figure 1). The UMDL ontology is described in stylized natural language, and you may also view the implementation in description logic (Loom).
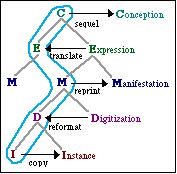
Figure 1 - A work with five derivation relations
Generating the knowledge base involved mapping data from MARC to the ontology, and reasoning about the data to establish relationships. More specifically, we generated the knowledge base in four steps:
- Convert binary MARC data to tagged text. We map MARC fields and values to ontology concepts with a set of control files that identify the MARC fields and codes, and establish priorities and conditions to resolve cases where several MARC values produce one ontology value, or where one MARC fields can produce several ontology values.
- Extract coded attributes and values from natural language comments in the tagged text. This was done in a rapid, mindless way that could also be achieved computationally with natural language processing (we spent an average of only 40 seconds per record on the transcription).
- Convert the tagged text to Loom TELL statements. At this stage every value is treated as a distinct object.
- Reason about the data to establish relationships. First, merge matching conceptions, expressions, and manifestations. Then, based on transcribed clues and other information, deduce relations between works. When a preceding work is not in the collection, generate knowledge-base objects that reflect what we do know about it.
Frequently, the MARC data is imprecise or partial. It is often difficult or impossible to identify relationships with absolute certainty, even for trained professionals with hours of time available to play detective! To represent this data in the knowledge-base, therefore, we decided to use "tentative" relations in cases where we were not able to deduce relationships with confidence.
We identify four important classes of benefits that may result from this work.
- Useful queries. Users can ask for translations in languages that they speak; for versions that include additional indexes; for screenplay adaptations, sequels, critical reviews, and so on, and so on.
- Identifying rights. In particular, agent-based systems such as the UMDL will need ontology-based metadata to compute the licenses required to provide various services for particular works, to pay the appropriate copyright fees, and so on.
- Facilitating cataloging. To catalog a new work, librarians will add it to its family at the appropriate level of the work hierarchy. Characteristics that it shares with other members of the family will be automatically inherited.
- Sharing knowledge. Most generally, ontology will help us to integrate many overlapping databases of bibliographic information. Ideally, people playing many roles in many organizations will contribute to a shared, world-wide, but well-organized knowledge-base of information. Of course, this will require a lot of effort in both the technical and institutional realms.
The Beethoven Project was designed and implemented by Peter Weinstein. Gene Alloway and Judy Ahronheim added their deep and extensive knowledge of library matters.
- Peter Weinstein. 1998. Ontology-Based Metadata: Transforming the MARC Legacy. Proceedings of the Third ACM Digital Library conference, Pittsburgh, PA, USA, June 1998.
- Peter Weinstein and Gene Alloway. 1997. Seed Ontologies: growing digital libraries as distributed, intelligent systems. Proceedings of the Second ACM Digital Library conference, Philadelphia, PA, USA, July 1997.
These papers are not immediately available due to copyright restrictions, but you may request copies.
The UMDL ontology.
An online interface for browsing the knowledge base.
To mail Peter Weinstein.
To mail the UMDL Ontology group.