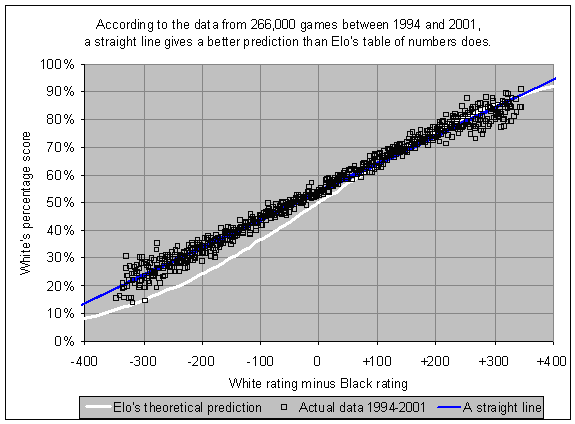
Another alternative to Elo is promoted by Jeff Sonas. The graphic below (taken from "The Sonas Rating Formula – Better than Elo?") shows a large number of chess games played by rated players. It seems that Sonas is (intentionally or not) conflating the first-mover advantage and a purported underlying linearity in the data. It is clear that White has a 50-point advantage (measured in ratings points), which is not captured by the Elo curve, making the Elo curve a straw man. This is easy to fix by mentally moving the Elo curve on that graph to left by 50 points. That is, the 50% point on the Elo curve should pass through the 50% mark on real data, or equivalently: the curve should reflect the empirical advantage to moving first.
Looking at the Elo-based NSA ratings curve (and a slight modification implemented in simulations by Robert Parker), together with a linear approximation shows a similar pattern. If we define a piecewise linear function p=max(min(.5+D/800,1),0) where D is the ratings difference and p the estimated probability of winning, it would differ by less than 2% from the current NSA ratings curve over the range from -300 to 300.
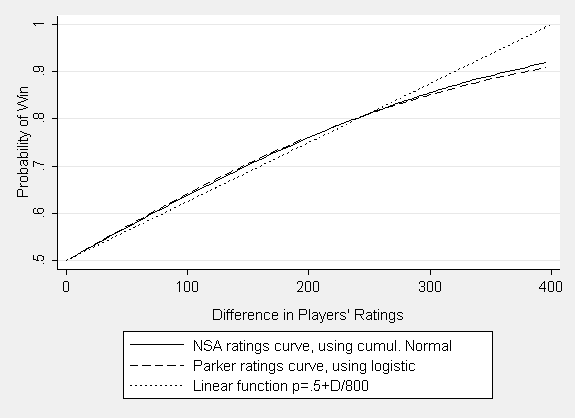
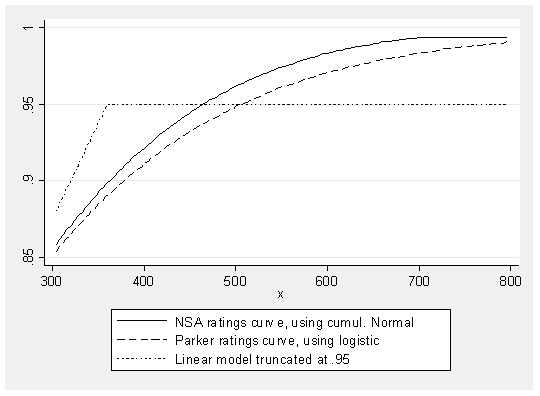
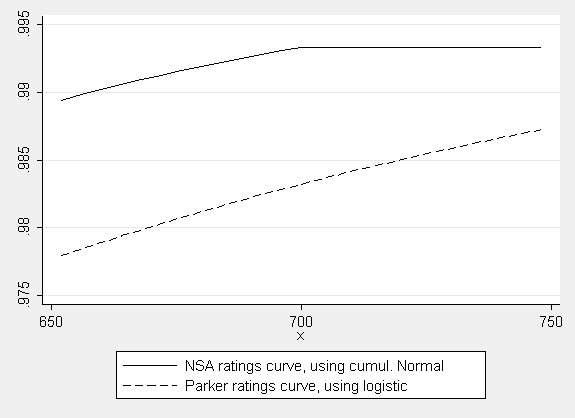
The central problem arises from using only the difference in
ratings. Assume you have parametrized the logistic so it fits the
empirical win probability of a 1300 rated player playing players rated
from 600 to 2000. You now have a win probability defined over the range
of all ratings differentials from -700 to 700. Will this fit the
empirical win probability of an 1100 rated player playing players rated
from 600 to 1800? There is no reason to think it will--the rating numbers
are a rank ordering, not an interval-ratio-level measurement (i.e. they
are not like temperature in degrees Kelvin, where the distance from 273 to
274 has the same physical interpretation as the distance from 300 to 301).
There is a solution--define the projected win probability as a
function of two ratings, Player 1 and Player 2 (it makes sense to keep
track of which player moved first, since even though the game is not
solvable through backwards induction the way chess is, there does seem to
be an advantage to playing first). Once you define the projected
probability of winning over any two pairs of ratings, the ratings scheme
should be nearly self-enforcing, in the sense that the empirical win
percentages should not move around too much, and the projected win
probabilities will by definition be close to observed proportions for all
possible matchups.
Note that estimating the projected win probability as a function of two
ratings implies fitting a surface to the data, rather than a curve, so a
200-point advantage would imply a different probability of winning for two
players rated 1300 and 1100 than two players rated 1600 and 1400. One way
of doing this would be to estimate kernel regressions of win on opponent's
rating, for first and second movers, for each ratings level, using
tournament data over a medium-length timespan, say over a two-year window.
Kernel regression, or local polynomial regression, is a non-parametric
(this should be in quotes, because of course there are parameters, but
that's what the techniques are called) way of fitting a curve to data.
The main parameter is the bandwidth of the kernel, which controls
how smooth the fitted curve looks, but the point is mainly that you do not
constrain the curve to be in the linear, logistic, or other family of
functions--it is free to match the data very closely.
Some preliminary investigations using 7 years
of tournament data from cross-tables.com demonstrates that
the ogive ratings curve used by
the NSA seems to systematically underestimate the winning chances of the
lower-rated player and systematically overestimate the winning chances of
the higher-rated player. This may be due to the total absence of any
model of luck in the theory underlying the Elo system (developed for
chess, where there is no luck component, essentially). A model that
includes luck would likely predict that the mean influence of chance on
the expected outcome of the game is
different for different pairs of ratings (i.e. stronger players rely less
on lucky draws) which would mean that the standard deviation used in
an Elo-style model should vary across ratings levels, either producing
curves with different standard deviations for each ratings level
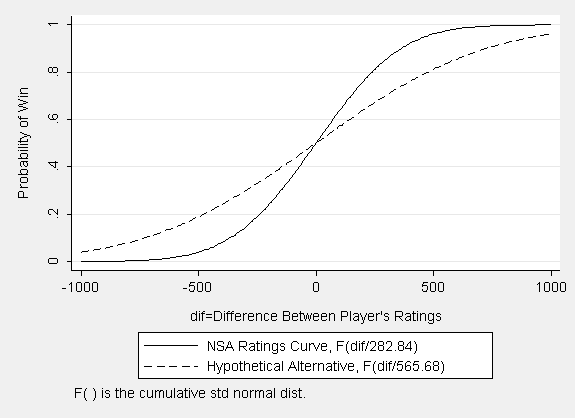
(for an example of a
what a ratings curve might look like using a single fixed
standard deviation parameter that exceeds the NSA parameter by a factor
of two, click
here) or, if the standard deviation should vary with both players'
ratings,
producing curves that look nothing like a cumulative normal.
Note, however, that any alternative ratings curve (estimated from past
data, say) would have to be applied to past events in some way (though the
pairings would have been different in past tournaments under the
counterfactual hypothesis of using a different ratings curve) to see if a
proposed alternative continued to match past performance once "revised"
ratings were calculated. Tricky stuff.
To paraphrase an email from Steven
Alexander, it is possible that the problem
is not the rating curve. John
Chew's tests showed a corrected curve would
need to be repeatedly corrected, and a discussion in The Mathematics
of
Games, by John D. Beasley (1989 Oxford), Ch. 5 (which
was copied to cgp on 12 Dec 2003) argued that the families of ratings
systems
under consideration are not particularly sensitive to the choice of a ratings
curve. The system's problems can be overstated compared to what else is
possible because the desired qualities are inconsistent.
In a sense, I agree with both of these points. If the NSA committed to
using a new ratings curve, whether a cumulative normal, or a
logistic, or a piecewise linear curve, it would make little difference in
the long run (say, after a year or so). Individual ratings might be
different, but percentile ranks should be largely unchanged (at least, in
the thought experiment where ability is largely unchanged), because the
interpretation of a rating X, or a ratings advantage N, would change just
enough to drive everyone back to the same situation. If you want to match
the empirical distribution of win percentages by ratings differentials,
and you change the ratings curve, then you change what a given ratings
advantage means, and ratings will change, perhaps until you are right back
in a similar
position as you were before. I think this is part of what Steven
Alexander meant by "the system's problems can be overstated
compared to what else is possible because the desired qualities are
inconsistent." The other part might concern the occasional proposals to modify
the multiplier, or bonus points, or what have you.
Let me call "hypothesis A" the notion that "a change to the ratings
curve would be followed by a short period where actual win percentages
match predicted ones, followed by a gradual return to the previous
situation, as described above." Now let me state a conjecture: hypothesis
A is true when the same ratings curve applies to all ratings level, but
not otherwise. I think this is true because a ratings system that assigns
numbers and treats them as interval-level data (when they are in fact
ordinal) is going to run into this problem. But if you allow the ratings
curve to differ by ratings level, you are treating the numbers as a level
of data that is a kind of hybrid between interval-level data and
ordinal-level data. If you didn't understand this discussion, stay
tuned. Once I work out the details, I'll write up a version that someone
who hasn't taken a statistics course will find easy to understand.
{kind=link}